
Literatur Review Terhadap Metode, Aplikasi dan Dataset Peringkasan Dokumen Teks Otomatis untuk Teks Berbahasa Indonesia
DOI:
https://doi.org/10.25299/itjrd.2020.vol5(1).4688Keywords:
Literatur Review, Peringkas Teks, Text Summarization, Bahasa IndonesiaAbstract
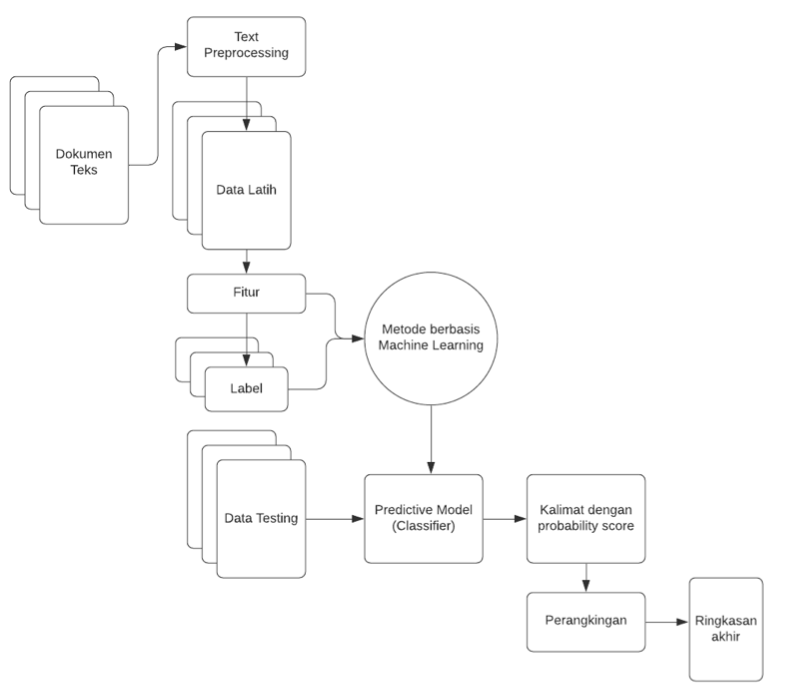
Saat ini, kebutuhan akan mesin peringkas dokumen teks menjadi semakin nyata karena semakin banyaknya informasi digital yang tersedia baik online maupun offline. Mesih peringkas dokumen teks dibutuhkan agar pembacaan dan pencarian informasi menjadi lebih cepat. Literatur review ini membahas metode, aplikasi, dataset dan Teknik evaluasi yang dapat diimplementasikan untuk riset di bidang peringkasan dokumen untuk teks berbahasa Indonesia. Kami melakukan review terhadap berbagai teknik text summarization, baik unsupervised maupun supervised, dataset yang dapat digunakan sebagai baseline dalam pengembangan sebuah metode dan evaluation measure yang tepat. Literature review ini juga akan menjelaskan sejauh apa perkembangan riset di bidang text summarization untuk dokumen berbahasa Indonesia.
Downloads
References
W. Yulita, S. Priyanta, and Azhari, “Automatic Text Summarization Based on Semantic Network and Corpus Statistics,” Indonesian Journal of Computing and Cybernetics Systems, 2019.
P.P. Tardan, A. Erwin, K.I. Eng and W. Muliady, “Automatic Text Summarization Based on Semantic Analysis Approach for Documents in Indonesian Language,” in International Conference on Information Technology and Electrical Engineering, 2013.
G. Yapinus, A. Erwin, M. Galinium and W. Muliady, “Automatic Multi-Document Summarization for Indonesian Documents Using Hybrid Abstractive- Extractive Summarization Technique,” in International Conference on Information Technology and Electrical Engineering, 2014.
A. R. Deshpande and Lobo L. M. R. J., “Text Summarization using Clustering Technique,” International Journal of Engineering Trends and Technology, 2013.
D. Annisa and M.L. Khodra, “Query-based Summarization for Indonesian News Article,” in International Conference on Advanced Informatics, Concepts, Theory, and Applications, 2017.
N. F. Saraswati, I. Indriati and R.S. Perdana, “Peringkasan Teks Otomatis Menggunakan Metode Maximum Marginal Relevance Pada Hasil Pencarian Sistem Temu Kembali Informasi Untuk Artikel Berbahasa Indonesia,” Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 2018.
P. Bhaskar and S. Bandyopadhyay, “A Query Focused Multi Document Automatic Summarization,” in Pacific Asia Conference on Language, Information and Computation, 2010, p.p 545-554.
D. T. Massandy and M.L. Khodra, “Guided Summarization for Indonesian News Articles,” in International Conference on Advanced Informatics, Concepts, Theory, and Applications, 2014.
P. E. Gennest and G. Lapalme, “Fully Abstractive Approach to Guided Summarization,” in Annual Meeting of the Association for Computational Linguistics, 2012, p.p. 354-358.
A. Ardianto, J. Praghantha and V. Christiani .M, “Perancangan Peringkas Berita Otomatis Dengan Memperhatikan Sinonim Menggunakan Metode Weight of Feature,” Jurnal Ilmu Komputer dan Sistem Informasi, 2013.
W.F. Chen, S. Syed, B. Stein, M. Hagen and M. Hattest, “Abstractive Snippet Generation,” in International World Wide Web Conference Committee, 2020.
A. Indriani, “Maximum Marginal Relevance Untuk Peringkasan Teks Otomatis Sinopsis Buku Berbahasa Indonesia,” in Seminar Nasional Teknologi Informasi dan Multimedia, 2014, p.p 29-34.
M. Alam and M. Kakkar, “Email Summarization-Extracting Content from the Email,” International Journal of Innovative Research in Computer and Communication Engineering, 2015.
D. Anggraini and L. Wulandari, “Peringkasan Teks Artikel Ilmiah Berbahasa Indonesia Menggunakan Teknik Ekstraktif dan Fitur Kalimat Untuk Dokumen Tunggal,” in Seminar Nasional Rekayasa Komputer dan Aplikasinya, 2015, p.p. 126-130.
Ayana, Y.K. Lin and Z.Y. Liu, “Recent Advances on Neural Headline Generation,” Journal of Computer Science and Technology, 2015.
Y. E. Ariska, W. Maharani and M.S. Mubarok, “Peringkasan Review Produk Berbasis Fitur Menggunakan Semantic Similarity Scoring dan Sentence Clustering,” in e-Proceeding of Engineering, 2016, p.p. 5323-5331.
D. K. Gaikwad and C.N. Mahender, “A Review Paper on Text Summarization,” International Journal of Advanced Research in Computer and Communication Engineering, 2016.
E. Eris, V. Christiani .M and C. Pragantha, “Penerapan Algoritma Textrank Untuk Automatic Summarization Pada Dokumen Berbahasa Indonesia,” Jurnal Ilmu Teknik dan Komputer, 2017.
R. Adelia, S. Suyanto and U.N. Wisesty, “Indonesian Abstractive Text Summarization Using Bidirectional Gated Recurrent Unit,” International Conference on Computer Science and Computational Intelligence, 2019.
G. Garmastewira and M.L. Khodra, “Summarizing Indonesian News Articles Using Graph Convolutional Network,” Journal of ICT, 2019.
C. Khatri, G. Singh and N. Parikh, “Abstractive and Extractive Text Summarization using Document Context Vector and Recurrent Neural Networks,” in International Conference on Knowledge Discovery & Data Mining, 2018.
J. Cheng and M. Lapata, “Neural Summarization by Extracting Sentences and Words,” in Annual Meeting of the Association for Computational Linguistics, 2016, p.p. 484-494.
P.M. Sabuna and D.B. Setyohadi, “Summarizing Indonesian Text Automatically by Using Sentence Scoring and Decision Tree,” in International Conferences on Information Technology, Information Systems and Electrical Engineering, 2017.
P.G. Somantri, A. Komarudin and R. Ilyas, “Peringkasan Teks Otomatis Berita Berdasarkan Klasifikasi Kalimat Menggunakan Support Vector Machine,” in Seminar Nasional Teknologi dan Informatika, 2018.
I.N. Akhmad, A. S. Nugroho and B. Harjito, “Peringkasan Multidokumen Otomatis dengan Menggunakan Log-Likelihood Ratio (LLR) dan Maximal Marginal Relevance (MMR) untuk Artikel Bahasa Indonesia,” Jurnal Linguistik Komputasional, 2018.
M. Koupaee dan W.Y. Wang, “WikiHow: A Large-Scale Text Summarization Dataset,” arXiv, 2018.
J. Carbonell dan J. Goldstein, “The Use of MMMR Diversity-Based Reranking For Reordering Documents and Producing Summaries,” in Special Interest Group on Information Retrieval, 1998, p.p. 335-336.
R. Mihalcea dan P. Tarau, “TextRank: Bringing Order into Texts,” in Conference on Empirical Methods in Natural Language Processing, 2004.
K. Kurniawan dan S. Louvan, “INDOSUM: A New Benchmark Dataset for Indonesian Text Summarization,” in International Conference on Asian Language Processing, 2018.
C.Y. Lin, “ROUGE: A Package for Automatic Evaluation of Summaries,” in in Annual Meeting of the Association for Computational Linguistics, 2004.
A. Malahyari, S. Pouriyeh, M. Assefi, S. Safaiei, E.D. Trippe, J.P. Gutierrez and K. Kochut, “Text Summarization Techniques: A Brief Survey,” International Journal of Advanced Computer Science and Applications, 2017.
D.K. Gaikwad and C.M. Mahender, “A Review Paper on Text Summarization,” International Journal of Advanced Research in Computer and Communication Engineering, 2016.
C.D. Manning, P. Raghavan and H. Schütze, “Introduction to Information Retrieval,” Cambridge University Press, 2008.
F. Chollet, “Deep Learning with Python,” Manning Publications, 2017.
P. Kouris, G. Alexandridis and A. Stafylopatis, “Abstractive Text Summarization Based on Deep Learning and Semantic Content Generalization,” in Annual Meeting of the Association for Computational Linguistics, 2019.
Y. Yuliska and T. Sakai, “A Comparative Study of Deep Learning Approaches for Query-Focused Extractive Multi-Document Summarization,” in International Conference on Information and Computer Technologies, 2019, p.p. 153-157.
T. Mikolov, I. Sutskever, K. Chen, G Corrado and J. Dean, “Distributed Representations of Words and Phrases and their Compositionality,” in Advances in Neural Information Processing Systems, 2013.
J. Pennington, R. Shocker and C.D. Manning, “GloVe: Global Vectors for Word Representation,” in Conference on Empirical Methods in Natural Language Processing, 2016, p.p. 1532-1543.
A. Joulin, E. Grave, P. Bojanowski and T. Mikolov, “Bag of Tricks for Efficient Text Classification,” in Conference of the European Chapter of the Association for Computational Linguistics, 2017.
J. Devlin, M.W. Chang, K. Lee and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of NAACL-HLT, 2019.
Z. Cai, N. Lin, C. Ma and S. Jiang, “Indonesian Automatic Text Summarization Based on A New Clustering Method in Sentence Level,” in International Conference on Big Data Engineering, 2019.
J.H. Lee, S. Park, C. M. Ahn and D. Kim, “Automatic generic document summarization based on non-negative matrix factorization,” Information Processing and Management: an International Journal, 2009.
A. Ridok, “Peringkasan Dokumen Bahasa Indonesia Berbasis Non-Negative Matrix Factorization (NMF),” Jurnal Teknologi Informasi dan Ilmu Komputer, 2014.
S. Silvia, P. Rukmana, V. R. Aprilia, D. Suhartono, R. Wongso and M. Meiliana, “Summarizing Text for Indonesian Language by Using Latent Dirichlet Allocation and Genetic Algorithm,” in Proceeding of International Conference on Electrical Engineering, Computer Science and Informatics, 2014, p.p. 148-153.
E.Y. Hidayat, F. Firdausillah, K. Hastuti, I. N. Dewi and A. Azhari, “Automatic Text Summarization Using Latent Drichlet Allocation (LDA) for Document Clustering,” International Journal of Advances in Intelligent Informatics, 2015.
M. Zoph, E. L. Mencia and J. Fürnkranz, “Which Scores to Predict in Sentence Regression for Text Summarization?,” in the Proceedings of NAACL-HLT, 2018, p.p. 1782-1791.
M. Zoph, E. L. Mencia and J. Fürnkranz, “Which Scores to Predict in Sentence Regression for Text Summarization?,” in the Proceedings of NAACL-HLT, 2018, p.p. 1782-1791.
Y. Yuliska and T. Sakai, “Query-Focused Extractive Summarization based on Deep Learning: Comparison of Similarity Measures for Pseudo Ground Truth Generation”, in the Data engineering and Information Management Forum, 2019.
A. Najibullah, “Indonesian Text Summarization based on Naïve Bayes Method”, in the Proceeding of the International Seminar and Conference, 2015, p.p. 67-78.
R. Indrianto, M. A. Fauzi and L. Muflikhah, “Peringkasan Teks Otomatis Pada Artikel Berita Kesehatan Menggunakan K-Nearest Neighbor Berbasis Fitur Statistik”, Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 2017.
Y. Kim, “Convolutional Neural Networks for Sentence Classification”, in Conference on Empirical Methods in Natural Language Processing, 2014, p.p. 1746-1751.
F. Koto, “A Publicly Available Indonesian Corpora for Automatic Abstractive and Extractive Chat Summarization”, in International Conference on Language Resources and Evaluation, 2016, p.p. 801-805.
Q. Mei and C. X. Zai, “Generating Impact-Based Summaries for Scientific Literature”, in Annual Meeting of the Association for Computational Linguistics, 2008, p.p. 816-824.
V. Qazvinian and D. R. Radev, “Scientific paper summarization using citation summary networks”, in International Conference on Computational Linguistics, 2008, p.p. 689-696.
Downloads
Published
How to Cite
Issue
Section
License
This is an open access journal which means that all content is freely available without charge to the user or his/her institution. The copyright in the text of individual articles (including research articles, opinion articles, and abstracts) is the property of their respective authors, subject to a Creative Commons CC-BY-SA licence granted to all others. ITJRD allows the author(s) to hold the copyright without restrictions and allows the author to retain publishing rights without restrictions.











