
Analisis Data Sosial Media Twitter Menggunakan Hadoop dan Spark
DOI:
https://doi.org/10.25299/itjrd.2020.vol4(2).4099Abstract
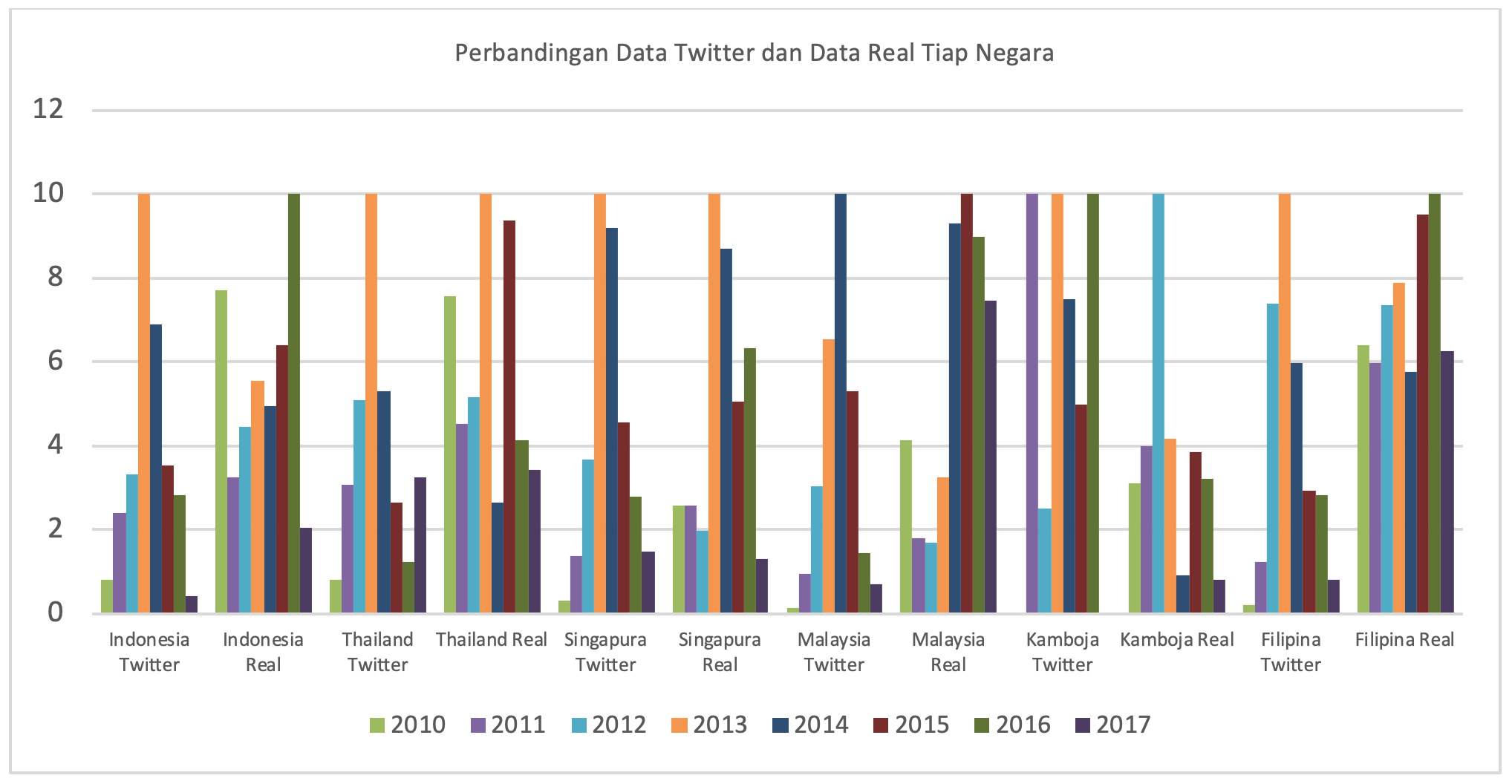
Big data merupakan sumber data yang memiliki volume yang besar, variasi yang banyak, dan aliran data yang sangat cepat. Contoh big data antara lain data dari media sosial dan query pencarian Google. Data tersebut mampu melacak aktivitas penyakit dan data yang ada tersedia setiap saat. Pengolahan big data bukanlah suatu hal yang mudah, sehingga diperlukan suatu tools yang dapat membantu proses pengolahan terhadap big data. Salah satu tools tersebut adalah hadoop. Meskipun kinerja hadoop lebih unggul daripada RDBMS tradisional, akan tetapi pengolahan data menggunakan hadoop belum maksimal. Sehingga, diperlukan pengolahan data yang lebih cepat. Salah satu cara untuk meningkatkan kecepatan pengolahan data ialah menerapkan spark untuk proses pengolahan data yang ada di HDFS (Hadoop Distributed File System). Pada penelitian ini dilakukan plotting tren dan pemetaan pada data Demam Berdarah Dengue (DBD) yang berasal dari media sosial twitter. Penelitian ini bertujuan untuk membuat visualisasi data yang diperoleh dari twitter dengan menggunakan hadoop dan spark dalam memantau perkembangan DBD di wilayah Asia Tenggara. Hasil dari plotting tren menunjukkan adanya hubungan yang kuat antara data twitter, data asli kejadian DBD yang diperoleh dari WHO. Penelitian ini juga melakukan pengujian performa hadoop dan spark. Semakin besar alokasi memory executor yang diterapkan serta semakin besar dan serupa alokasi maksimal memory scheduler yang diterapkan pada tiap node, maka waktu yang dibutuhkan untuk menyelesaikan task semakin singkat. Akan tetapi, pada titik tertentu konfigurasi hadoop dan spark menemui titik puncaknya, sehingga jika alokasi diperbesar menghasilkan hasil yang sama.
Downloads
References
J. Hurwitz, A. Nugent, F. Halper, and M. Kaufman, Big Data for Dummies. New Jersey: John Wiley & Sons, Inc.
K. Basuki, H. Palit, and L. Dewi, “Implementasi hadoop: Studi kasus pengolahan data peminjaman perpustakaan universitas kristen petra,” Jurnal Infra, vol. 3, no. 2, pp. 226–232,.
B. RA, O. MJ, and B. WA, Mapping collective behavior in the big-data era. Cambridge University.
C. A. M. Toledo, C. Degener, L. Vinhal, G. Coelho, W. Meira, C. Codeco, and M. Teixeira, “Dengue prediction by the web: Tweets are a useful tool for estimating and forecasting dengue at country and city
level,” PLOS, vol. 11, no. 7, pp. 1–13,.
M. Carlos, M. Nogueira, and R. Machado, “Analysis of dengue outbreaks using big data analytics and social networks,” in 4th International Conference on Systems and Informatics (ICSAI, Hangzhou.
A. Ryanto, “Analisis kinerja framework big data pada cluster tervirtualisasi : Hadoop mapreduce dan apache spark,” Makassar.
A. S. Foundation, “Apache hadoop,” available:. [Online]. Available: https://hadoop.apache.org/.
S. Oliviandi, A. Osmond, and R. Latuconsina, “Implementation apache spark on big data based hadoop distributed file system,” e-Proceeding of Engineering, vol. 5, no. 1, pp. 1005–1012,.
A. S. Foundation, “Apache spark,” available:. [Online]. Available: https://spark.apache.org/.
Downloads
Published
How to Cite
Issue
Section
License
This is an open access journal which means that all content is freely available without charge to the user or his/her institution. The copyright in the text of individual articles (including research articles, opinion articles, and abstracts) is the property of their respective authors, subject to a Creative Commons CC-BY-SA licence granted to all others. ITJRD allows the author(s) to hold the copyright without restrictions and allows the author to retain publishing rights without restrictions.











